Asset Management
Asset Management
Asset management isn’t just about documentation, my friend! It’s essential to plan for system failures, account for aging equipment, and handle changes carefully. By thinking ahead, you can smoothly manage network hardware, software, and resources. A little humor, a bit of planning, and the job gets done!
Network Failures & Redundancy
1. MTBF & MTTR
- MTBF (Mean Time Between Failures):
- The average time between failures for devices.
- Vendors/technicians use this to budget for repairs or replacements.
- MTTR (Mean Time To Repair):
- The average time to fix a device after it fails.
- Costs must also be considered.
Example:
- An ISP’s SLA (Service Level Agreement) specifies their MTBF/MTTR.
- If the internet goes down, they guarantee it will be back up in 2-4 hours.
2. Redundancy: Backup Plan
- Concept:
- Keep two or more identical items/connections for a task.
- If one fails, the other takes over.
- Goal:
- Eliminate Single Points of Failure (SPoF).
- Ensure critical components (e.g., internet connection, server hard disk) are redundant.
Trade-off:
- Higher investment, but lower risk.
- Example: A redundant ISP is costly, but if the primary fails, business operations continue uninterrupted.
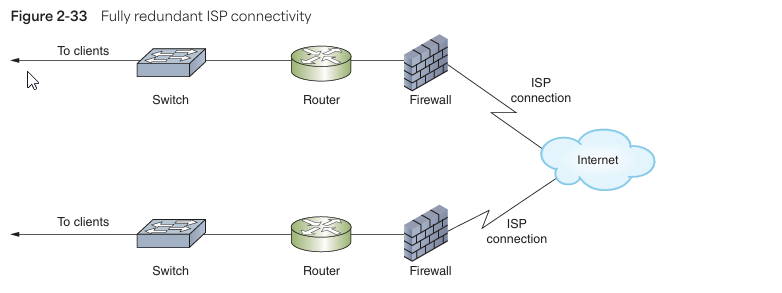
3. Single Points of Failure (SPoF)
- Common SPoFs:
- ISP link (e.g., cable cut during construction).
- Critical devices: Firewall, router, switch.
- Solution:
- Design with full redundancy (Refer to Figure 2-33!).
4. Fault Tolerance Components
- Redundant Hardware:
- NICs, power supplies, cooling fans, processors.
- If one fails, the other activates automatically (failover).
- Hot-Swappable Parts:
- Hot spare: Pre-installed, ready for instant replacement.
- Cold spare: Not installed; requires manual replacement (slower process).
Pro Tip:
- When buying switches/routers, prefer failover-capable or hot-swappable components.
5. Key Takeaways
- Estimate failure and repair times using MTBF/MTTR.
- Redundancy = Safety Net, but it comes at a cost.
- Identify SPoFs and make them redundant.
- Reduce downtime with failover-capable components.
System Life Cycle & Configuration Management
System Life Cycle Management
Phases:
- Requirements Analysis:
- Understand network/business needs. Clarify “What is required?”
- Design Planning:
- Plan everything from goals to minute details.
- Development & Testing:
- Purchase equipment and test before deployment.
- Implementation:
- Deploy new equipment and establish a stable baseline.
- Documentation & Maintenance:
- Monitoring + updated documentation = quicker problem resolution!
- Evaluation:
- Perform cost-benefit analysis. Decide to upgrade, replace, or retire.
Key Point:
- No system lasts forever! Adapt → Maintain → Retire.
Configuration Management (CM)
Goal:
- Keep the system in its desired state and track changes.
Features:
- Follow Standards: Industry/government best practices.
- Monitor Changes: Alert on unauthorized changes.
- Limit Permissions: ”Keep unauthorized users out!”
- Track Changes: Document “who, what, when” for every change.
Stages:
- Discovery:
- Take inventory of current configurations. Baseline = Golden State.
- Version Control:
- Maintain a history of changes. Helps with rollback/audit.
- Monitoring:
- Check performance and detect “configuration drift.”
- Automation:
- Use tools to automate monitoring and version control.
- Auditing:
- Review past changes (for compliance and effectiveness).
Pro Tip:
- Backing up production configurations is as important as backing up data!
Decommissioning (EOS/EOL)
Key Terms:
- EOS (End-of-Support):
- Vendor stops providing updates/fixes. Risky!
- EOL (End-of-Life):
- Product sales/production stop, but limited support may continue.
Decommissioning Steps:
- Check Dependencies:
- “Is any other system dependent on this?”
- Backup + Document:
- Backup configurations and data, then test.
- Inform Stakeholders:
- Notify everyone to avoid disruptions.
- Phase-wise Shutdown:
- Shut down services one by one for a smooth transition.
Mantra:
- “Plan before EOS, or you’ll face security risks!”
Cheat Sheet
| Concept | Key Action |
|---|---|
| Life Cycle | Plan → Test → Deploy → Maintain → Retire |
| CM | Track changes + Automate + Audit |
| Decommission | Backup → Document → Phase-out |
Change Management
Change Management Basics
Why Needed?
- Technology upgrades, security patches, changing user needs.
- Goal: Minimize downtime and maintain efficiency.
Golden Rule:
- Even small changes require planning → Document & Approve!
Types of Changes
A. Software Changes
| Type | Purpose | Example |
|---|---|---|
| Patch | Fix bugs/vulnerabilities (minor update) | Security patch for OS. |
| Upgrade | Major feature/functionality boost | New version of CRM software. |
| Rollback | Revert failed changes | Undo a buggy firmware update. |
B. Hardware Changes
- Small: Replace HDD, add printer.
- Big: Upgrade network cabling, VoIP systems.
- Firmware Updates: Test compatibility! (Manufacturer’s docs = Bible).
Change Management Steps
- Stop Auto-Patching: Manually review before deployment.
- Assess Need:
- Security patch? Mandatory.
- New features? Evaluate cost vs benefit.
- Read Vendor Docs: Compatibility, impact, rollback steps.
- Test in Isolated Environment:
- Virtual/isolated network → Test → Document findings.
- Define Scope:
- Affected users/devices? (Partial/Full rollout).
- Schedule Maintenance Window:
- Off-hours + Notify users/admins.
- Take Backup: Configs, data, firmware – everything!
- Implement + Test in Real-Time:
- User-like testing + Stress test.
- Prepare Rollback Plan: If it fails, follow vendor docs to undo.
- Document & Close:
- Log changes, update network maps, inform stakeholders.
Change Request Documentation
Key Components (Simplified Table 2-4):
| Field | Example |
|---|---|
| Requester/Approver | Network Admin → IT Director. |
| Change Type | Accounting app patch. |
| Reason | Bug fixes in reports. |
| Rollback Plan | Revert to v2.1 if fails. |
| Downtime | 2 hours (Sunday 2AM-4AM). |
Pro Tip:
- Log even small changes (e.g., security patches) in the database.
5. Approval & Project Management
- Minor Changes: Approved by department head.
- Major Changes: Review board + Additional docs (cost/risk analysis).
- Change Coordinator:
- Trained PM → Handles training, coordination, budget.
- Post-change debriefing for improvements.
6. Network Documentation Updates
Post-change, update:
- Network maps (new VLANs/subnets).
- IP address allocations.
- Physical device locations (e.g., relocated printers).
7. Cheat Sheet: Rollback Options (Table 2-3)
| Change Type | Rollback Method |
|---|---|
| OS Patch | Use uninstall utility. |
| Client Software | Reinstall old version. |
| OS Upgrade | Restore from pre-upgrade backup. |
Note:
- Keep old hardware for a while – it might come in handy!
8. Key Takeaways
- Plan → Test → Backup → Document.
- Notify Users – avoid downtime surprises!
- Rollback plan is a must – no exceptions.
- Documentation = Future Proofing.
Summary
Network Management Cheat Sheet
MTBF vs MTTR
- MTBF (Mean Time Between Failures):
- Average time between device failures. “How long does it last?”
- MTTR (Mean Time To Repair):
- Average time to fix a device + calculate costs!
Mantra:
“High MTBF, Low MTTR = Best combo!”
Redundancy = Backup Plan
- Goal: Eliminate Single Points of Failure (SPoF).
- Trick:
- One fails? The other activates automatically (e.g., backup ISP, dual power supplies).
- Drawback: Costly, but better than downtime!
System Life Cycle
Phases:
- Design: Understand requirements.
- Implement: Test and deploy.
- Maintain: Monitor + Update configurations.
- Retire: Replace/upgrade at EOS (End-of-Support).
Key: “No system is forever!”
4 Types of Software Changes
| Type | Purpose | Example |
|---|---|---|
| Install | Add new software | CRM, Accounting Tools |
| Patch | Fix bugs/vulnerabilities | Security updates |
| Upgrade | Boost features + performance | New OS version |
| Rollback | Revert failed update | Undo buggy patch |
Hardware Changes:
- Firmware updates = Follow manufacturer’s docs!
Change Management Rules
- Document Everything:
- Why change? Who approved? Rollback plan?
- Test First: Try in an isolated environment.
- Notify Users: Give advance warning for downtime.
- Take Backup: Backup configs/data = Lifesaver!
Golden Rule:
“Never make changes without documentation, or the blame game will begin!”
Final Tip:
- MTBF/MTTR + Redundancy + Life Cycle + Change Docs = Shortcut to Becoming a Network Guru!
This post is licensed under CC BY 4.0 by the author.