Network Troubleshooting
Network Troubleshooting
🔧 Network Troubleshooting
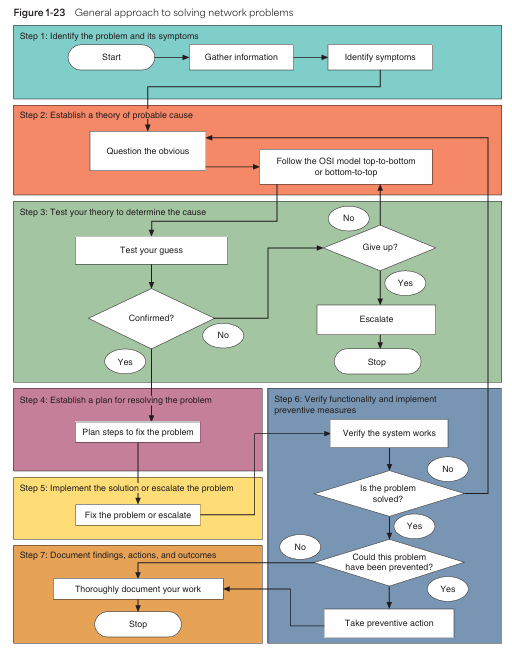
🔍 Step 1: Identify the Problem
- First, observe the symptoms (e.g., browser not opening websites, local file sharing not working).
- Communicate with the user clearly: Has anything changed recently? Has this issue occurred before?
- Check the scope of the problem: Is it affecting one system or the whole network?
- Try to reproduce the problem: Attempt to recreate the issue to better understand it.
- Pro Tip: If there are multiple issues, address them one by one, based on priority.
🤔 Step 2: Develop a Theory of Probable Cause
- Make an educated guess based on the symptoms.
- Use the OSI model to structure your approach:
- Bottom-to-Top: If it’s likely a hardware issue (e.g., loose cable, faulty NIC).
- Top-to-Bottom: If it’s clearly a software/configuration issue (e.g., invalid credentials).
- Apply “divide and conquer”: Eliminate one possibility at a time to narrow down the root cause.
🧪 Step 3: Test the Theory to Determine the Cause
- Before implementing any solution, test your theory to verify it’s the actual cause.
- If the fix is complex or expensive, validate the theory first.
- If your guess is wrong, don’t worry — try the next theory or escalate the issue to the next support tier.
🧠 Step 4: Establish a Plan of Action
- Prepare a proper action plan before applying any fix.
- Evaluate the impact of the fix: Will it affect users, applications, or data?
- Follow change management protocols, especially in production:
- Include the need for the change, cost, mitigation of disruption, and rollback strategy.
🛠️ Step 5: Implement the Solution or Escalate
- Inform affected users ahead of time: “There might be a short disruption.”
- Take backups of all important data and current system configurations.
- Make one change at a time and verify if the issue is resolved before proceeding.
- If the issue is outside your scope or responsibility, escalate it to someone with appropriate authority or technical access.
✅ Step 6: Verify Full System Functionality & Apply Preventive Measures
- Perform complete system testing after applying the fix.
- Ask the user to test it too — different permissions and configurations may impact their experience.
- Monitor the system over the next few days to ensure stability.
- Think ahead: What can prevent this issue from happening again?
- More preventive maintenance? Add a network monitoring tool?
📝 Step 7: Document Findings, Actions & Outcomes
- Log all actions in the organization’s help desk or ticket tracking system:
- Include: who reported it, department, contact info, time of report, symptoms, resolution steps, technician name, and time taken.
- If a unique solution or key learning was involved, record it for future reference.
- This documentation helps build a knowledge base for the entire IT team to use later.
🧪 Real-Life Example – Case Summary
🖥️ Problem: Desktop couldn’t access the internet or local network resources.
🧠 Theory: A technician was working near the desk the previous evening — possibly unplugged cable.
✅ Test: Found the cable unplugged and lying on the floor.
🔌 Fix: Reconnected the cable — connection restored.
📝 Documentation: Simple fix, so just verbally informed nearby colleagues. But in a real-world setting, always log it formally.
🎯 Key Takeaways for Quick Review
- Bottom-up = suspect hardware issues first.
- Top-down = suspect software or configuration errors.
- Always document your actions and resolution.
- Test before applying any fix.
- Notify users, back up everything, and plan for rollback.
- After fixing the problem, think prevention — monitoring, documentation, and maintenance.
This post is licensed under CC BY 4.0 by the author.